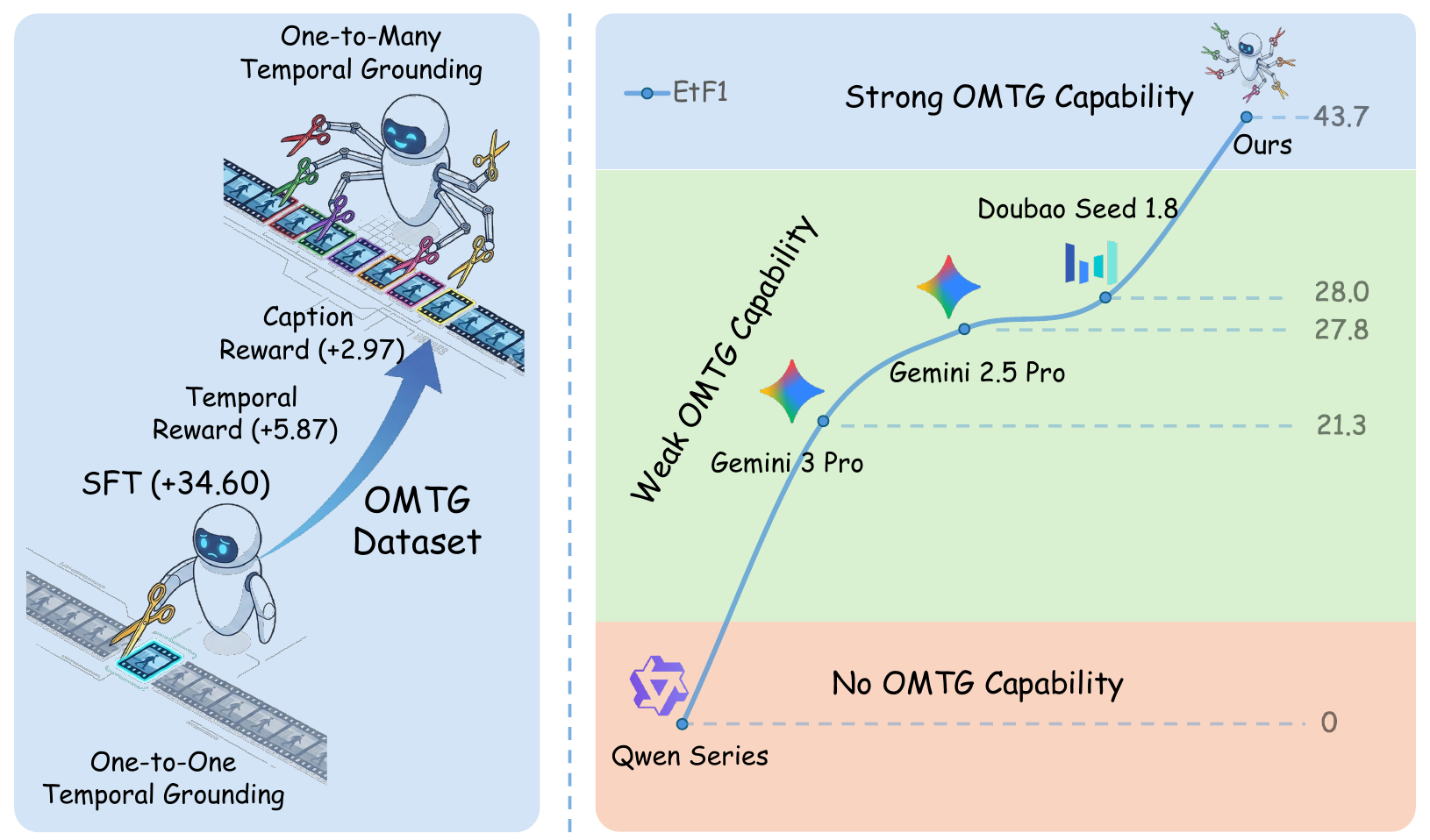
Temporal Grounding aims to localize video segments corresponding to a textual query. Prior work predominantly focuses on single-segment retrieval, while real-world videos often contain multiple recurring events for the same query. We formulate this setting as One-to-Many Temporal Grounding and present a systematic solution including the first comprehensive OMTG benchmark, new evaluation metrics, a 56K-sample OMTG dataset, and an SFT+RL training recipe with temporal and caption rewards.
OMTG-4B achieves 43.65 EtF1 on OMTG Bench, outperforming Gemini 2.5 Pro and Seed-1.8 by 15.85 and 15.61 points, respectively. The benchmark is available on Hugging Face and has been integrated into VLMEvalKit for standardized evaluation.
In OMTG, high temporal IoU can hide severe counting errors: a model may merge several occurrences into one long segment or hallucinate extra segments while still maintaining large overlap. We therefore introduce Count Accuracy (C-Acc) for event cardinality perception and Effective Temporal F1 (EtF1), which requires both correct count and accurate temporal localization.

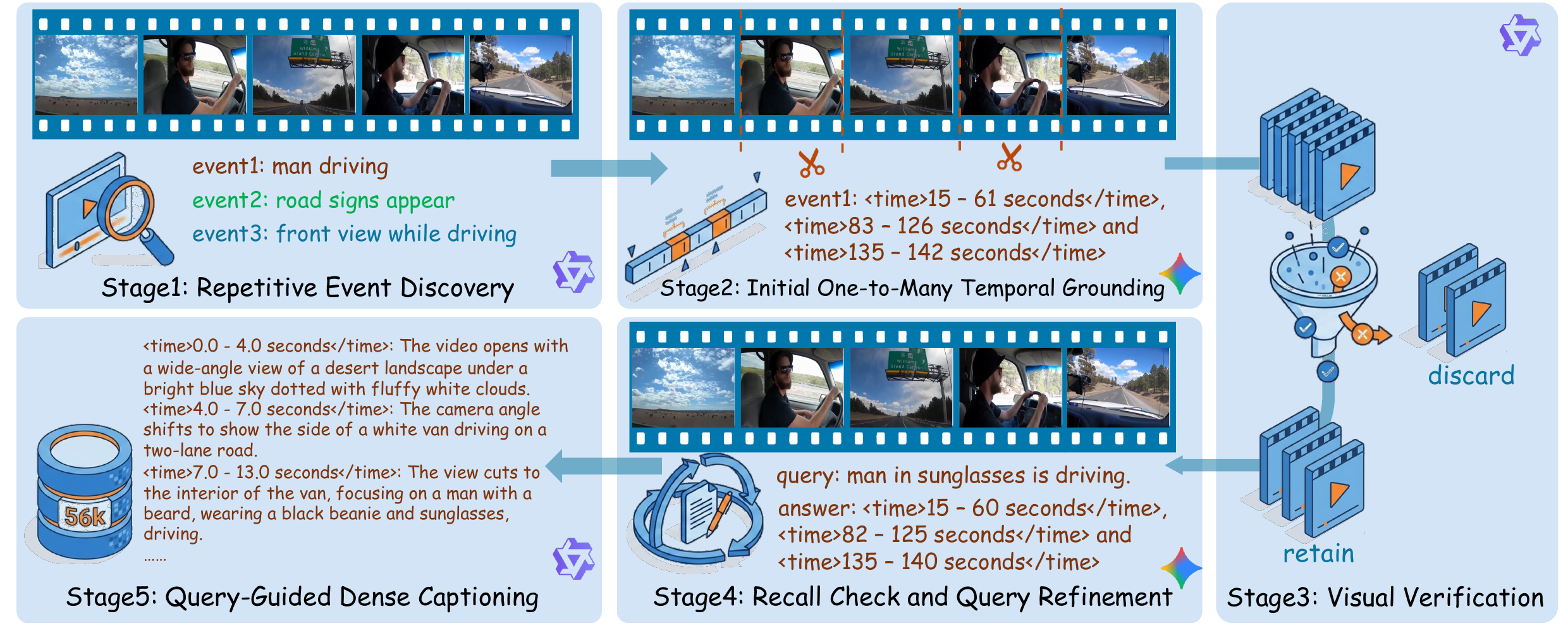
We construct OMTG-56K, a high-quality instruction tuning dataset created through repetitive event discovery, initial one-to-many grounding, strict visual verification, recall check, query refinement, and query-guided dense captioning. The final dataset contains 46K samples for SFT and 10K samples for RL.
OMTG Bench contains 340 manually curated samples from diverse domains. The number of ground-truth segments ranges from 2 to 20, and the average video length is 221.6 seconds, making the benchmark a direct test of both event counting and boundary precision. OMTG Bench is supported by VLMEvalKit, so new models can be evaluated through a widely used MLLM evaluation toolkit.
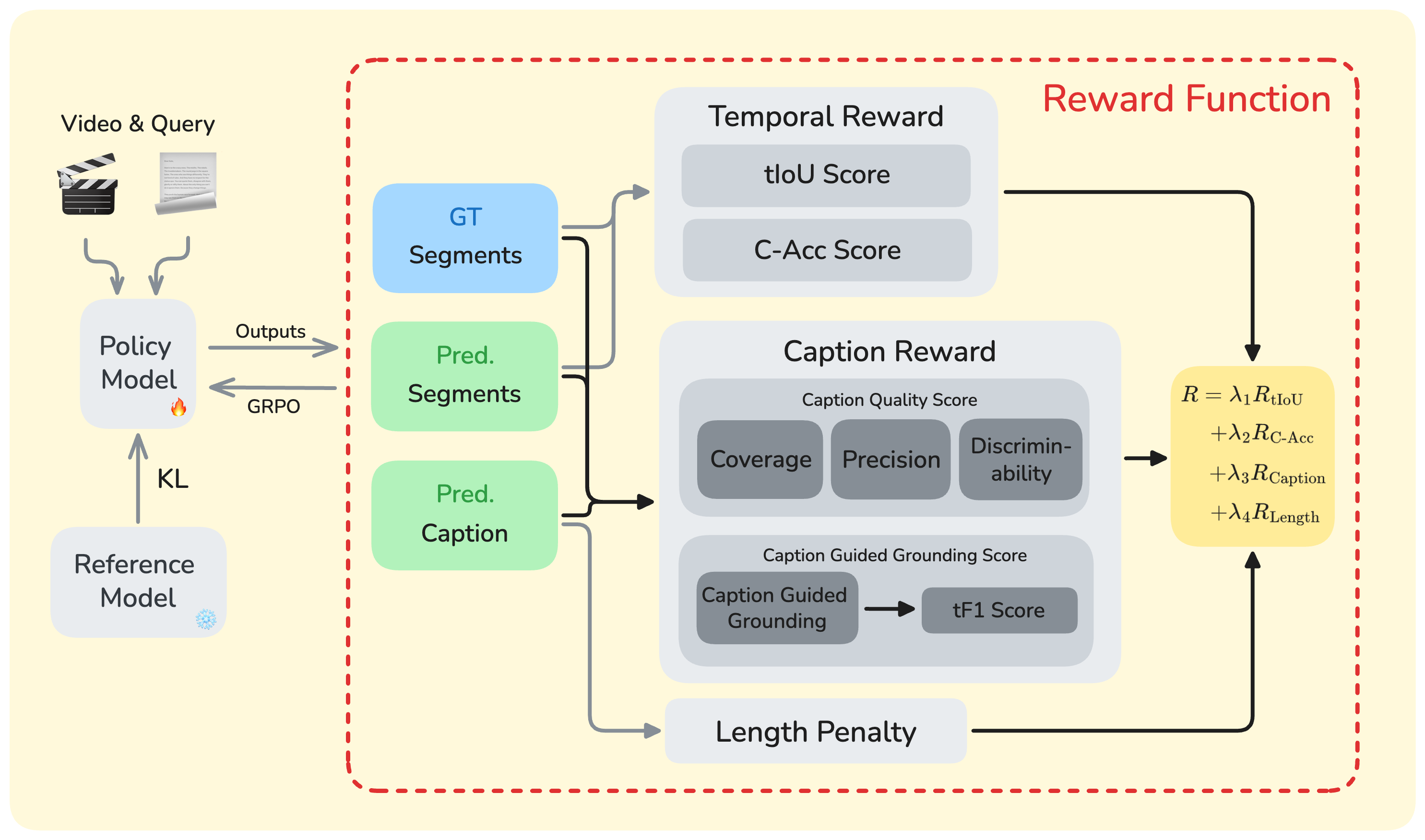
We start from Qwen3-VL-4B and first perform supervised fine-tuning on OMTG-56K to establish the ability to generate multiple temporal intervals. We then optimize the model with GRPO using a composite reward that combines temporal overlap, count correctness, caption quality, and length control.
The caption reward evaluates whether intermediate dense captions cover all ground-truth occurrences, align well with temporal boundaries, and distinguish repeated instances with sufficient context. This encourages reasoning that is both complete and precise.
| Model | C-Acc | tF1@0.3 | tF1@0.5 | tF1@0.7 | tIoU | EtF1 |
|---|---|---|---|---|---|---|
| Seed-1.8 | 38.12 | 67.13 | 54.67 | 38.79 | 56.81 | 28.04 |
| Gemini-2.5-Pro | 50.94 | 55.72 | 43.57 | 27.97 | 43.24 | 27.80 |
| Gemini-3-Pro | 30.63 | 58.30 | 47.75 | 29.89 | 47.63 | 21.30 |
| Qwen3-VL-4B | 0.31 | 37.07 | 26.75 | 17.93 | 30.42 | 0.21 |
| UniTime | 0.00 | 35.27 | 30.15 | 23.58 | 37.12 | 0.00 |
| TimeLens-8B | 0.00 | 39.14 | 32.76 | 22.58 | 32.38 | 0.00 |
| OMTG-4B | 55.63 | 73.46 | 65.40 | 48.96 | 61.24 | 43.65 |
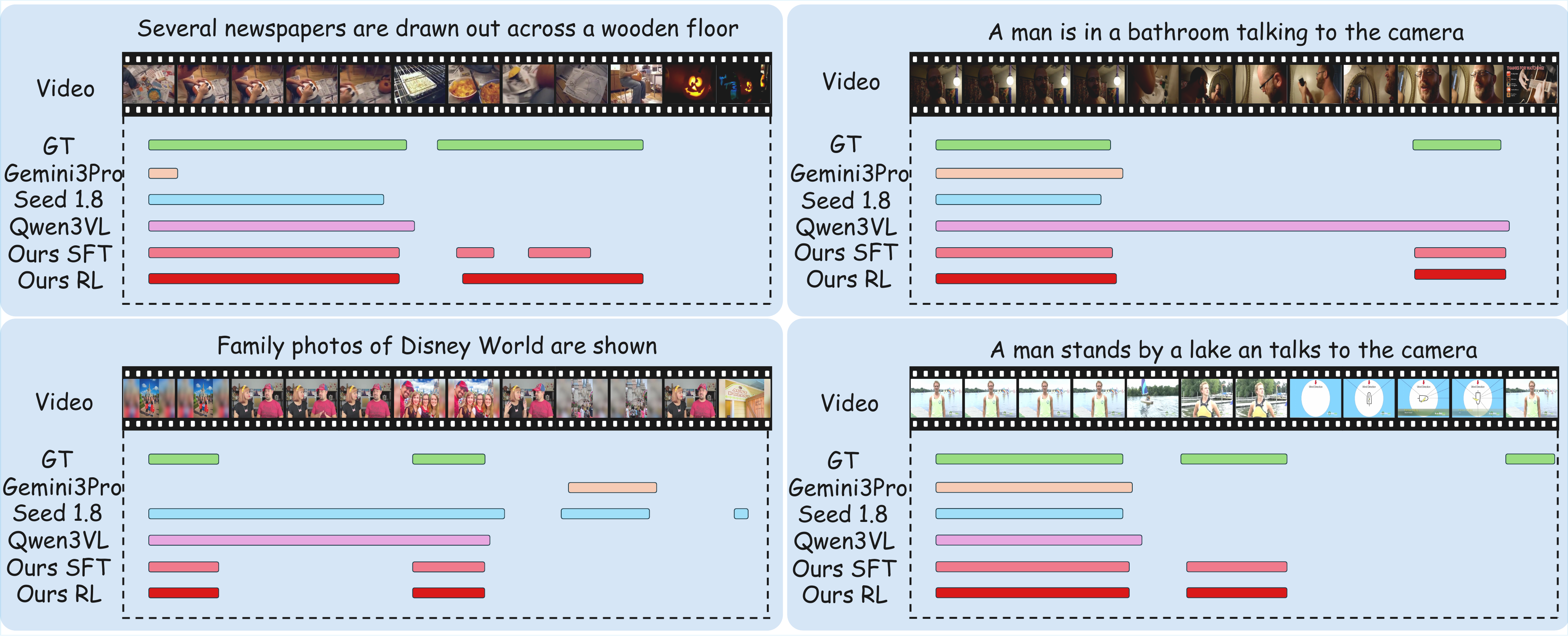
OMTG-4B obtains the best score across all reported metrics. SFT raises EtF1 from 0.21 to 34.81, while RL with temporal and caption rewards further improves it to 43.65.
Existing video MLLMs often retrieve only a single occurrence or incorrectly merge distinct events into one continuous span. OMTG-4B better separates repeated events and localizes all disjoint occurrences.
@inproceedings{omtg2026,
title = {Towards One-to-Many Temporal Grounding},
author = {Qi Xu and Yue Tan and Shihao Chen and Jiahao Meng and Anna Wang and Shunping Ji and Hao Fei and Jason Li},
booktitle = {Proceedings of the International Conference on Machine Learning (ICML)},
year = {2026},
url = {https://arxiv.org/abs/2606.06294},
}